
Introduction to Machine Learning
Machine learning is a subset of artificial intelligence (AI) that enables systems to learn from data, identify patterns, and make decisions with minimal human intervention. It’s used in various applications, from recommendation systems and image recognition to natural language processing and autonomous vehicles.
Key Concepts:
- Learning from Data: Machine learning models are trained on data to recognize patterns and make predictions or decisions.
- Generalization: The ability of a model to perform well on unseen data, not just the data it was trained on.
Supervised vs. Unsupervised Learning
Supervised Learning: In supervised learning, the model is trained on a labeled dataset, where the input data is paired with the correct output. The goal is to learn a mapping from inputs to outputs that can be applied to new, unseen data.
- Examples:
- Classification: Assigning labels to inputs (e.g., spam detection).
- Regression: Predicting continuous values (e.g., house prices).
Unsupervised Learning: In unsupervised learning, the model is given unlabeled data and must find hidden patterns or structures within it. There is no explicit output to predict, and the goal is to discover the underlying structure of the data.
- Examples:
- Clustering: Grouping similar data points together (e.g., customer segmentation).
- Dimensionality Reduction: Reducing the number of features while retaining important information (e.g., PCA).
Key Algorithms: Linear Regression, Logistic Regression, k-Nearest Neighbors
Linear Regression: Linear regression is a supervised learning algorithm used for predicting a continuous target variable based on one or more input features. It assumes a linear relationship between the input variables and the target variable.
- Equation:

from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
Logistic Regression: Logistic regression is a classification algorithm used to predict binary outcomes (e.g., yes/no, 0/1). It models the probability of a categorical dependent variable based on one or more predictor variables using a logistic function.
- Equation:
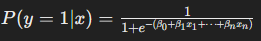
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
k-Nearest Neighbors (k-NN): k-NN is a simple, non-parametric algorithm used for both classification and regression. It classifies a data point based on the majority class among its k-nearest neighbors or predicts a value by averaging the values of its k-nearest neighbors.
- Key Concept: Distance metric (e.g., Euclidean distance) to find the closest neighbors.
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
Model Evaluation Metrics
Evaluating the performance of a machine learning model is crucial to understand its effectiveness and make necessary adjustments.
For Classification:
- Accuracy: The ratio of correctly predicted instances to the total instances.
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, predictions)
- Precision and Recall: Precision is the ratio of true positive predictions to the total predicted positives, while recall is the ratio of true positives to all actual positives.
from sklearn.metrics import precision_score, recall_score
precision = precision_score(y_test, predictions)
recall = recall_score(y_test, predictions)
- F1 Score: The harmonic mean of precision and recall, providing a balance between the two.
from sklearn.metrics import f1_score
f1 = f1_score(y_test, predictions)
- Confusion Matrix: A table used to describe the performance of a classification model by showing the true vs. predicted classifications.
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, predictions)
For Regression:
- Mean Absolute Error (MAE): The average of the absolute differences between predicted and actual values.
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_test, predictions)
- Mean Squared Error (MSE): The average of the squared differences between predicted and actual values.
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_test, predictions)
- R-squared: The proportion of the variance in the dependent variable that is predictable from the independent variables.
from sklearn.metrics import r2_score
r2 = r2_score(y_test, predictions)
Understanding the basics of machine learning, including different types of learning, key algorithms, and evaluation metrics, is fundamental for anyone looking to delve into the field of data science. These concepts lay the groundwork for building, training, and evaluating machine learning models that can solve real-world problems.
#MachineLearningBasics #SupervisedLearning #UnsupervisedLearning #LinearRegression #LogisticRegression #kNearestNeighbors #ModelEvaluation #ClassificationMetrics #RegressionMetrics #MachineLearningAlgorithms #DataScience #DataAnalysis #PythonForDataScience #MLModeling #MachineLearning #AI



Hey people!!!!!
Good mood and good luck to everyone!!!!!